


Intro
In the previous article, we explored how the Transformer architecture (TA) [Vaswani et al., 2023]) has revolutionized the development of modern large language models (LLMs), quickly becoming the industry standard. We examined the key requirements behind its design, discovering that self-attention allows the TA to understand relationships between words, even those far apart, resulting in much richer context awareness. Additionally, the use of multi-head attention enables the model to analyse input from multiple perspectives simultaneously, capturing a wide range of relationships and patterns for superior performance. This makes the architecture especially well-suited for large and complex tasks. Because the TA processes sequences in parallel, it relies on positional encodings to preserve the order of words. Finally, feed-forward layers further enhance the model’s ability to capture intricate patterns and features at each position.
The goal of this article is to present the Transformer Architecture, starting with a high-level overview before delving into its details. We will also see that, while the TA is widely regarded as the standard, most commercial models today implement carefully adapted variants, often based solely on the decoder component, to best suit their key requirements/use cases.
High Level Architecture
Following the requirements and solutions outlined in the preceding section, Figure 1 depicts the high-level Transformer Architecture (TA).
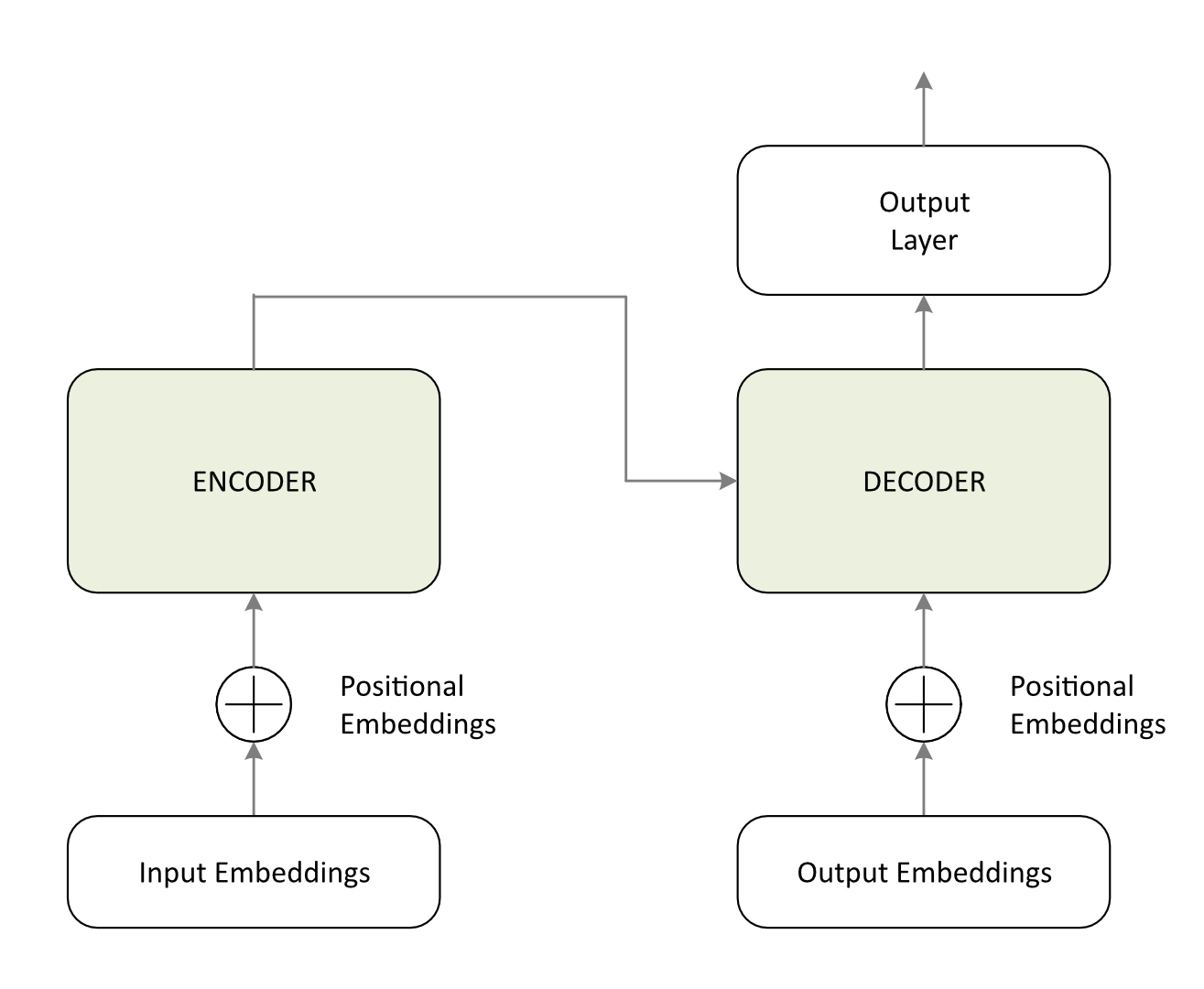
The TA relies on an Encoder-Decoder structure designed to execute complex sequence-to-sequence tasks with high accuracy. This framework is optimized for tasks involving the processing of input modalities (such as text, audio, or images) into internal vector representations to generate corresponding outputs. As discussed later, several popular models adopt variations of this architecture.
Encoder
The encoder processes the input sequence to generate context-aware representations, capturing token relationships through mechanisms such as self-attention, multi-head attention, and feed-forward layers. These representations encode both the semantic meaning of individual tokens and their contextual relationships, providing a comprehensive understanding of the input sequence.
Decoder
The decoder utilizes these representations to generate the output sequence iteratively. It employs a dual attention mechanism: self-attention, which models relationships between tokens within the output sequence, and cross-attention, which focuses on relevant segments of the encoder’s output. This ensures the generation of coherent and contextually appropriate outputs by leveraging both the input context and previously generated tokens.
Output Layer
Finally, the output layer generates predictions for the subsequent token. In language modelling tasks, this is typically implemented via a Softmax layer that produces a probability distribution over the vocabulary; the token with the highest probability is selected as the next element in the sequence. This layer is essential for translating internal vector representations into human-readable formats.
The Encoder-Decoder structure is highly effective for tasks such as machine translation, summarization, and question answering. Furthermore, the Transformer’s modular design offers significant flexibility, allowing the encoder and decoder to function independently for tasks such as classification or generation. This versatility has established the Transformer architecture as the foundation of most modern large language models.
Detailed architecture.
The following diagram illustrates the detailed architecture of the encoder and decoder components

This section integrates the concepts introduced in previous articles (it connects the dots). Before proceeding, it is important to understand the concept of Residual Connections since it is leveraged throughout the TA. These residual connections allow the model to retain information from earlier layers and mitigate the vanishing gradient problem. Vanishing gradients is a training problem where, during backpropagation, the gradients of the loss with respect to earlier-layer parameters become extremely small, approaching zero. As a result, those earlier layers learn very slowly or even stop learning because their weights no longer change meaningfully. The solution consists of adding the input to each sub-layer (e.g., self-attention or feed-forward) to its output before being passed to the next layer. This mechanism enables the model to learn deeper representations while preserving critical information from preceding layers. With this foundation established, let us analyse each component in detail.
Inputs
The process begins with the input sequence, which consists of a series of tokens (e.g., words, sub-words, or characters) extracted from the text (tokenisation). These tokens are typically converted into the corresponding numerical representations (token IDs) using a predefined vocabulary.
Input Embeddings
Each token ID is mapped to a dense numerical vector (embedding) that represents its semantic meaning in a high-dimensional space. These embeddings are learned during training and capture linguistic relationships, such as synonyms or contextual similarities.
Positional Embeddings
Since the Transformer processes the input sequence in parallel, rather than sequentially like RNNs, it lacks an inherent sense of order. To address this, positional embeddings are added to the input embeddings. These are numerical vectors that encode the position of each token within the sequence, allowing the model to interpret the order of the tokens.
Encoder Component
The encoder is composed of multiple identical layers (e.g., 6 or 12 layers). Each layer consists of the following subcomponents:
- Multi-Head Attention: This mechanism allows the model to focus on different parts of the input sequence simultaneously. It computes attention scores for each token relative to all other tokens in the sequence, enabling the model to capture both short-range and long-range dependencies. Multiple attention “heads” operate in parallel, with each focusing on different aspects of the input (e.g., syntax, semantics, or positional relationships). The outputs of all heads are concatenated and linearly transformed to produce the final attention output.
- Add & Norm: A residual connection is applied by adding the input of the Multi-Head Attention layer to its output to prevent the vanishing gradient problem and to stabilise training. The result is then passed through a Layer Normalization step to ensure numerical stability and faster convergence.
- Feed-Forward Layer: A fully connected neural network is applied to each token’s representation independently. It consists of two linear transformations with a non-linear activation function (typically ReLU) in between. This layer transforms the token representations into richer, more abstract features, helping the model capture complex patterns in the data.
- Add & Norm: A residual connection and layer normalization are applied to the output of the cross-attention layer.
These steps are repeated for each layer in the encoder stack, progressively refining the input representations. The final output of the encoder is a set of context-aware vectors, where each vector corresponds to a token in the input sequence, encoding its meaning and its relationship to other tokens.
Output Embeddings and Positional Embeddings (Decoder Input)
The decoding process typically initiates with a special token, often called the start-of-sequence token (<SOS> or <BOS> begin-of-sequence). This signals the model to begin generating the output. As the sequence is generated, each token is converted into an embedding, and positional embeddings are added to encode the order, ensuring the decoder understands the structure of the target sequence.
Decoder Component
The decoder is also composed of multiple identical layers (e.g., 6 or 12) and processes the target sequence step by step. Each layer consists of the following subcomponents:
- Masked Multi-Head Attention: This mechanism focuses on the target sequence itself. However, to ensure the model does not access future information during training, a mask is applied to prevent attention to tokens beyond the current position. This preserves the auto-regressive property, ensuring the decoder generates the output sequence one token at a time.
- Add & Norm: A residual connection is applied by adding the input of the Masked Multi-Head Attention to its output, followed by layer normalization.
- Multi-Head Attention (Cross-Attention): This layer allows the decoder to attend to the encoder’s output. It computes attention scores between the target sequence and the encoder’s context-aware representations, enabling the decoder to focus on the most relevant parts of the input sequence to generate the next token.
- Add & Norm: A residual connection and layer normalization are applied to the output of the cross-attention layer.
- Feed-Forward Layer: Similar to the encoder, a fully connected neural network is applied to each token independently to further refine the representations.
- Add & Norm: Another residual connection and layer normalization are applied to the output of the feed-forward layer.
Output Layer
The final output of the decoder is passed through a Softmax layer, which generates a probability distribution over the entire vocabulary. The token with the highest probability is selected as the next word in the sequence. This process repeats iteratively until the entire output sequence is produced (e.g., a translated sentence or a response to a question).
In summary, both the encoder and decoder consist of multiple layers, with each layer further refining the representations. The number of layers and the embedding size are hyperparameters that determine the model’s capacity. The self-attention mechanism enables the capture of token relationships within the same sequence, while the cross-attention mechanism ensures the output is contextually aligned with the input. Finally, residual connections and layer normalization are critical for stabilizing training and ensuring effective learning without vanishing gradients.
Architectural deviations in modern models
Based on the available documentation, it is not always possible to determine the exact architecture used by various models, as the relevant design details are often only partially disclosed or not shared at all. As a result, this paragraph also draws on technical blogs and specialized online discussions, which may not be entirely reliable sources. Nevertheless, by cross-checking information from multiple papers, the following conclusions could be drawn.
In this paper, we have analysed the original TA (introduced in the influential paper Attention Is All You Need, [Vaswani et al., 2023]), which employs both an encoder and a decoder stack. However, modern large language models have evolved into specialized architectures tailored to their specific requirements and use cases.
Decoder-Only (Generative Models)
The vast majority of modern LLMs used for chat and content creation, including GPT-4, Llama 3, and Claude, seem to utilise a Decoder-Only architecture (see [Radford, A. et al., 2018], [Touvron, H., et al., 2023], [Belcic, Stryker, 2024]). This variation became a standard for LLM. This design is optimized for auto-regressive tasks, where the model predicts the next token in a sequence to generate coherent text.
Gemini also is built on a standard TA decoder only, similar to GPT-4 and Llama, but it is significantly modified to handle “native multimodality”. So, it is not just a standard decoder, but it is significantly modified for multimodal input. This allows the single model to process and reason over multiple modalities (text, images, audio, etc.), rather than bolting on separate modules for each modality (see [Google Gemini Team, 2023]).
Encoder-Only (Discriminative Models)
Models designed for search relevance, classification, and sentiment analysis, such as BERT and RoBERTa (see [Devlin, J., et al., 2018]), utilise an Encoder-Only architecture. These models process the entire input sequence simultaneously (bidirectionally) to understand context but are not designed to generate text.
Encoder-Decoder (Seq2Seq Models)
Models like T5 (Google) and the original Transformer retain both stacks, making them highly effective for sequence-to-sequence tasks like translation and summarization, though they are less common in general-purpose chat applications.
Conclusion
The Transformer Architecture (TA) is a neural network designed specifically for NLP (natural language processing) tasks. Unlike older models such as RNNs (recurrent neural networks) and LSTMs (long short-term memory networks), the Transformer processes sequential data, such as text, in parallel rather than word by word, making it significantly more efficient.
The key services that a TA must implement include:
- Capturing relationships between tokens: Achieved through the Self-Attention Mechanism, which allows the model to understand dependencies between words.
- Focusing on multiple aspects of the input: Enabled by Multi-Head Attention, which processes different relationships in parallel.
- Providing information about token order: Handled by Positional Encoding, which encodes the sequence order of tokens.
- Learning complex patterns: Accomplished through Feedforward Layers, which transform token representations.
- Stabilizing and accelerating training: Managed by Layer Normalization, which ensures consistent input distributions for each layer.
- Retaining information and improving gradient flow: Supported by Residual Connections, which help preserve information from earlier layers.
- Facilitating sequence-to-sequence tasks: Enabled by the Encoder-Decoder Structure, which is essential for tasks like machine translation.
- Efficiently processing large datasets: Achieved through Scalability and Parallelization, which allow the model to process tokens simultaneously.
- Converting text into numerical representations: Handled by Tokenization and Embedding, which transform text into a format the model can process.
- Generating predictions or outputs: Managed by the Output Layer, which produces the final results.
These components work together to make the TA a powerful and versatile tool for a wide range of tasks, from machine translation to text generation and beyond. The TA is particularly well-suited for LLMs for several reasons:
- Parallelization: Unlike other architectures such as RNNs, Transformers process tokens simultaneously, enabling efficient large-scale training.
- Contextual understanding: The self-attention mechanism captures relationships between words, regardless of their distance in the sequence.
- Scalability: The performance of Transformers improves predictably as the model size and the amount of training data increase, following Well thought through “scaling laws.”
- Transfer learning: Pretrained Transformers can be fine-tuned for a wide variety of downstream tasks, making them highly adaptable and reusable.
In summary, the TA has revolutionised NLP by providing a robust, scalable, and efficient framework for understanding and generating human language. Its ability to process large datasets, capture complex relationships, and adapt to diverse tasks makes it the backbone of modern large language models.
References
[Vaswani et al., 2023] Ashish Vaswani – Noam Shazeer – Niki Parmar – Jakob Uszkoreit – Llion Jones – Aidan N. Gomez – Łukasz Kaiser – Illia Polosukhin, Attention is all you need. 2 August 2023,
https://arxiv.org/pdf/1706.03762.pdf
[Devlin J. et al., 2018] Jacob Devlin – Ming-Wei Chang – Kenton Lee – Kristina Toutanova, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
https://arxiv.org/abs/1810.04805
[Google Gemini Team, 2023] Google Gemini Team, Gemini: A Family of Highly Capable Multimodal Models.
https://arxiv.org/abs/2312.11805
[Radford A. et al., 2018] Alec Radford – Jeffrey Wu – Rewon Child – David Luan – Dario Amodei – Ilya Sutskever, Language Models are Unsupervised Multitask Learners”.
https://t.ly/4RI02
[Touvron H. et al., 2023] Hugo Touvron – Thibaut Lavril – Gautier Izacard – Xavier Martinet – Marie-Anne Lachaux – Timothée Lacroix – Baptiste Rozière – Naman Goyal, – Eric Hambro – Faisal Azhar – Aurelien Rodriguez – Armand Joulin – Edouard Grave – Guillaume Lample, LLaMA: Open and Efficient Foundation Language Models.
https://arxiv.org/abs/2302.13971
[Belcic – Stryker, 2024] Ivan Belcic — Cole Stryker, What is Claude AI?. IBM, September 2024.
https://t.ly/K5LV1