


Introduzione
Nel precedente articolo abbiamo visto come l’architettura Transformer (TA) abbia rivoluzionato lo sviluppo dei moderni large language model (LLM), diventando rapidamente lo standard di riferimento nel settore. Abbiamo analizzato i requisiti chiave alla base del suo design, scoprendo che il meccanismo di self-attention consente alla TA di comprendere le relazioni tra le parole, anche quando sono distanti tra loro, offrendo così una consapevolezza del contesto decisamente più ricca.
Inoltre il modello è in grado di analizzare l’input da molteplici prospettive contemporaneamente, cogliendo una vasta gamma di relazioni e schemi e, allo stesso tempo, permettendo prestazioni superiori. Questo rende l’architettura particolarmente adatta a compiti ampi e complessi. Poiché la TA elabora le sequenze in parallelo, si affida alle codifiche posizionali per preservare l’ordine delle parole. Infine, i livelli feed-forward migliorano ulteriormente la capacità del modello di catturare schemi e caratteristiche complesse in diverse posizioni dell’input.
Per quanto la TA sia ampiamente considerata lo standard di riferimento, la maggior parte dei modelli LLM commerciali oggi disponibili ne implementa varianti attentamente adattate, spesso basate solo sul componente decoder, per rispondere al meglio ai propri requisiti primari.
Architecture di alto livello
Sulla base dei requisiti e delle relative soluzioni menzionate nell’articolo precedente, il seguente diagramma illustra l’architettura Transformer (TA) ad alto livello.
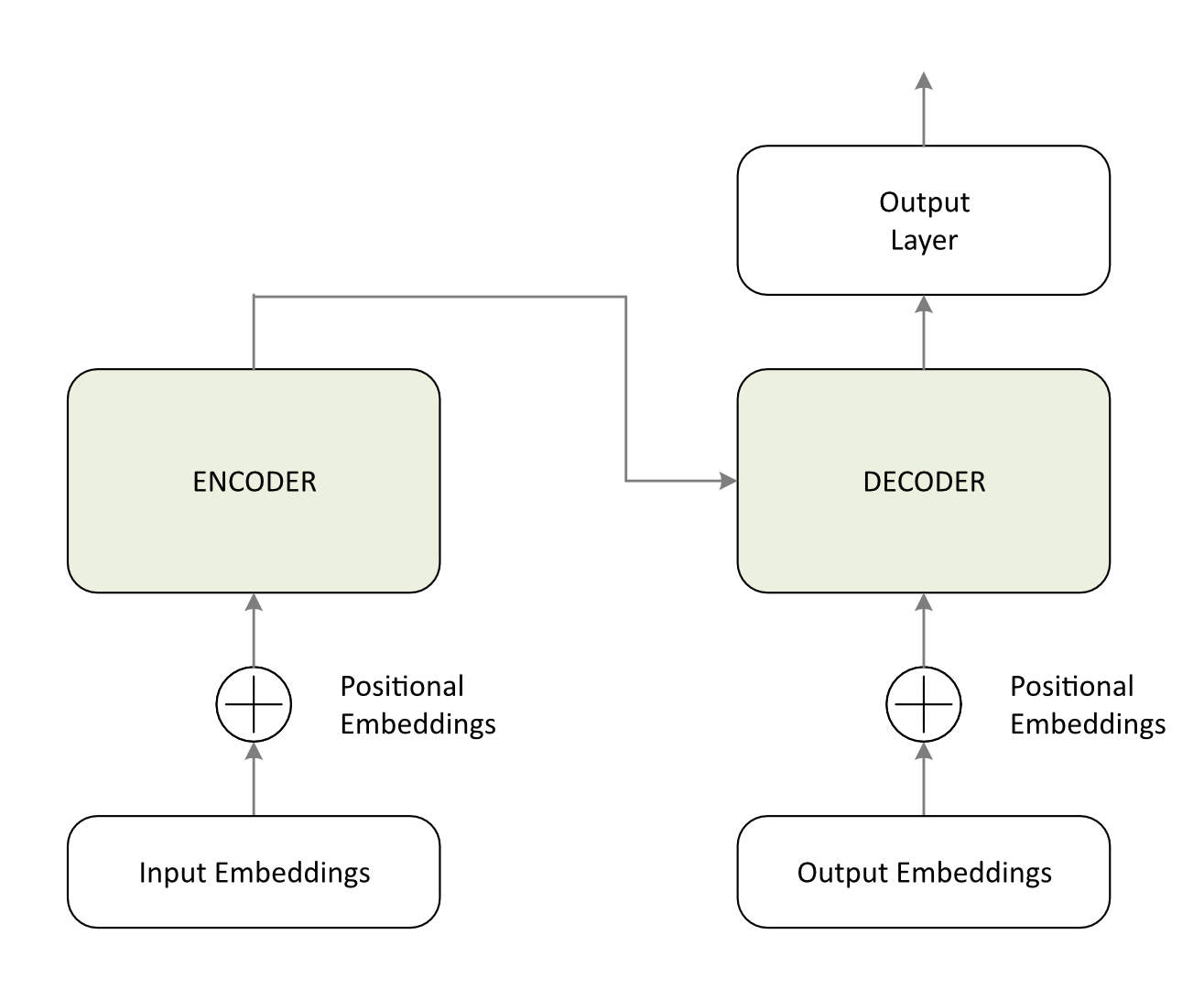
La TA si basa su una struttura Encoder-Decoder, progettata per gestire con elevata precisione compiti complessi di tipo sequence-to-sequence. Questa architettura è particolarmente adatta per attività in cui il modello elabora diverse tipologie di dati di input, come testo, audio o immagini, convertendoli in rappresentazioni interne tramite vettori e matrici, per poi generare i relativi output. Come vedremo successivamente, diversi modelli adottano varianti di questa architettura.
L’encoder elabora la sequenza di input e genera un insieme di rappresentazioni contestuali, catturando le relazioni tra i token attraverso meccanismi come la self-attention, la multi-head attention e i livelli feed-forward. Queste rappresentazioni codificano sia il significato dei token di input, sia le loro relazioni reciproche, fornendo una ricca comprensione contestuale della sequenza di input.
Il decoder riceve queste rappresentazioni contestuali dall’encoder e genera la sequenza di output, un token alla volta. Utilizza una combinazione di self-attention, per comprendere le relazioni tra i token nella sequenza di output, e di cross-attention, per focalizzarsi sulle parti rilevanti dell’output dell’encoder. Questo doppio meccanismo di attenzione assicura che il decoder possa generare output coerenti e contestualmente appropriati, sfruttando sia la sequenza di input, sia i token generati in precedenza.
Al termine del decoder, il livello di output (output layer) genera le previsioni per il token successivo nella sequenza. Per compiti come il language modelling, questo viene tipicamente implementato come un livello Softmax, che produce una distribuzione di probabilità sull’intero vocabolario. Il token con la probabilità più alta viene selezionato come parola successiva nella sequenza. Questo livello di output è fondamentale per tradurre le rappresentazioni interne del modello in output leggibili dall’uomo, come parole, frasi o altri dati strutturati.
Questa struttura Encoder-Decoder è particolarmente efficace per compiti quali la traduzione automatica, il riassunto del testo (text summarization) e il question answering, dove la comprensione delle relazioni tra sequenze di input e output è un aspetto fondamentale. Il design modulare del Transformer consente una grande flessibilità, poiché l’encoder e il decoder possono essere utilizzati anche indipendentemente per compiti come la classificazione del testo o la generazione di testo. Questa versatilità ha reso l’architettura Transformer la base della maggior parte dei moderni Large Language Models (LLM).
La Transformer Architecture in dettaglio
Il diagramma in figura 2 mostra la TA con un maggiore livello di dettaglio, entrando all’interno dei componenti Encoder e Decoder.
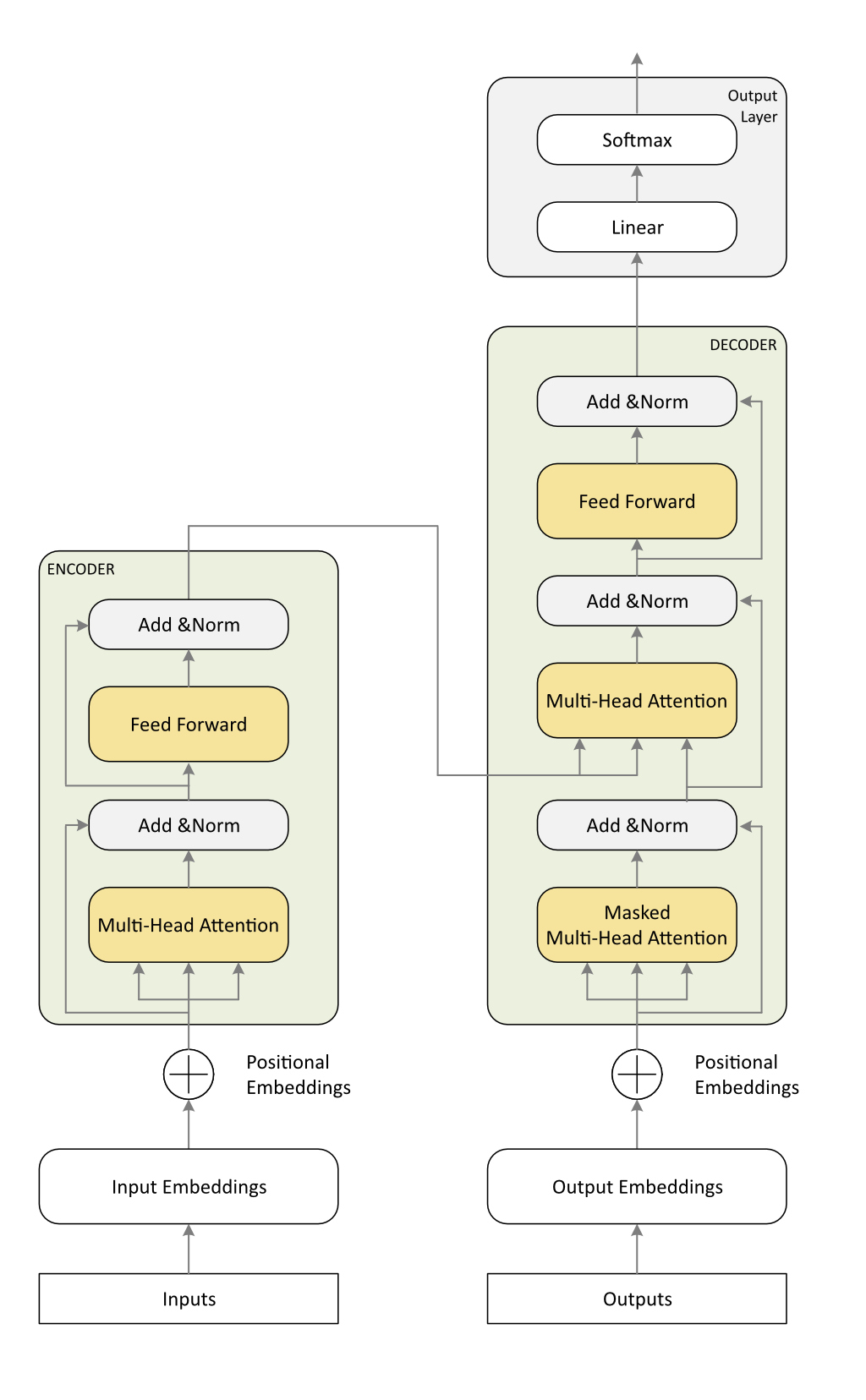
È giunto il momento di mettere insieme vari concetti introdotti negli articoli precedenti. Prima di procedere, è opportuno comprendere il concetto di Residual Connections (connessioni residue). Queste connessioni permettono al modello di conservare informazioni dei livelli precedenti per mitigare il problema del vanishing gradient (dispersione del gradiente). Si tratta di un problema che interviene nella fase di addestramento in cui, durante la backpropagation, i gradienti della perdita rispetto ai parametri degli strati più profondi diventano estremamente piccoli, tendendo a zero. Di conseguenza, questi strati iniziali finiscono per “imparare” molto lentamente o smettono del tutto, perché i loro pesi non riescono più a cambiare in modo significativo.
Con il Residual Connections, l’input di ogni sottolivello (ad esempio, self-attention o feed-forward) viene aggiunto al suo output prima di passare al livello successivo. Questo meccanismo consente al modello di apprendere rappresentazioni più profonde preservando al contempo le informazioni critiche dei livelli precedenti. Con queste basi, analizziamo ogni componente nel dettaglio.
Input
Il processo inizia con la sequenza di input, che consiste in una serie di token (ad esempio parole, sottoparole o caratteri) estratti dal testo. Questi token vengono tipicamente convertiti nelle corrispondenti rappresentazioni numeriche (ID dei token) utilizzando un vocabolario predefinito.
Input Embeddings
Ogni ID del token viene risolto in un vettore numerico denso (embedding) che ne rappresenta il significato semantico in uno spazio ad alta dimensione. Questi embedding vengono appresi durante l’addestramento (training) e catturano le relazioni linguistiche, come sinonimi o similarità contestuali.
Positional Embeddings
Poiché il Transformer elabora la sequenza di input in parallelo (anziché sequenzialmente come le RNN) non possiede un senso proprio dell’ordine. Per ovviare a questo problema, agli input embeddings vengono aggiunti i positional embeddings. Si tratta di vettori numerici che codificano la posizione di ciascun token all’interno della sequenza, consentendo al modello di interpretare l’ordine dei token.
Componente Encoder
L’encoder è composto da più livelli identici (ad esempio, 6 o 12 livelli). Ogni livello è costituito dai seguenti sottocomponenti.
- Multi-Head Attention: questo meccanismo permette al modello di concentrarsi simultaneamente su diverse parti della sequenza di input. Calcola i punteggi di attenzione per ogni token rispetto a tutti gli altri token della sequenza, consentendo al modello di catturare dipendenze sia a corto, sia a lungo raggio. Diverse head di attenzione operano in parallelo, ciascuna focalizzandosi su aspetti diversi dell’input (ad esempio sintassi, semantica o relazioni posizionali). Gli output di tutte le head vengono concatenati e trasformati linearmente per produrre l’output di attenzione finale.
- Add & Norm: una residual connection viene applicata sommando l’input del livello Multi-Head Attention al suo output. Questo aiuta a prevenire il problema del vanishing gradient e stabilizza l’addestramento. Il risultato passa poi attraverso un passaggio di Layer Normalization per garantire stabilità numerica e una convergenza più rapida.
- Feed-Forward Layer: una rete neurale completamente connessa (fully connected) viene applicata indipendentemente alla rappresentazione di ogni token. Consiste in due trasformazioni lineari con una funzione di attivazione non lineare (tipicamente ReLU) nel mezzo. Questo livello trasforma le rappresentazioni dei token in caratteristiche più ricche e astratte, aiutando il modello a catturare pattern complessi nei dati.
- Add & Norm: un’altra residual connection e uno strato di normalizzazione (layer normalization) vengono applicate all’output del livello feed-forward.
Questi passaggi vengono ripetuti per ogni livello dello stack dell’encoder, raffinando progressivamente le rappresentazioni di input. L’output finale dell’encoder è un insieme di vettori context-aware (consapevoli del contesto), dove ogni vettore corrisponde a un token nella sequenza di input, codificandone il significato e la relazione con gli altri token.
Output Embeddings e Positional Embeddings (Input del Decoder)
Il processo di decodifica inizia tipicamente con un token speciale, spesso chiamato token di inizio sequenza (<SOS> Start Of Sequence o <BOS> Begin Of Sequence). Questo segnala al modello di iniziare a generare l’output. Man mano che la sequenza viene generata, ogni token viene convertito in un embedding e vengono aggiunti i positional embeddings per codificare l’ordine, assicurando che il decoder comprenda la struttura della sequenza target.
Componente Decoder
Anche il decoder è composto da più livelli identici (ad esempio 6 o 12) ed elabora la sequenza target passo dopo passo. Ogni livello è costituito dai seguenti sottocomponenti:
- Masked Multi-Head Attention: questo meccanismo si concentra sulla sequenza target stessa. Tuttavia, per garantire che il modello non acceda a informazioni future durante l’addestramento, viene applicata una maschera (mask) per impedire l’attenzione ai token successivi alla posizione corrente. Questo preserva la proprietà auto-regressiva, assicurando che il decoder generi la sequenza di output un token alla volta.
- Add & Norm: una residual connection viene applicata sommando l’input della Masked Multi-Head Attention al suo output, seguita dallo strato di normalizzazione (layer normalization).
- Multi-Head Attention (Cross-Attention): questo livello permette al decoder di prestare attenzione all’output dell’encoder. Calcola i punteggi di attenzione tra la sequenza target e le rappresentazioni context-aware dell’encoder, consentendo al decoder di concentrarsi sulle parti più rilevanti della sequenza di input per generare il token successivo.
- Add & Norm: una residual connection e una layer normalization vengono applicate all’output del livello di cross-attention.
- Feed-Forward Layer: analogamente all’encoder, una rete neurale completamente conenssa (fully connected) è applicata a ciascun token in modo indipendente per raffinare ulteriormente le rappresentazioni.
- Add & Norm: un’altra residual connection e una layer normalization sono applicate all’output del livello feed-forward.
Output Layer
L’output finale del decoder passa attraverso un livello Softmax, che genera una distribuzione di probabilità sull’intero vocabolario. Il token con la probabilità più alta viene selezionato come parola successiva nella sequenza. Questo processo si ripete iterativamente fino alla produzione dell’intera sequenza di output (ad esempio, una frase tradotta o una risposta a una domanda).
Per terminare, sia l’encoder, sia il decoder sono composti da più livelli, e ogni livello raffina ulteriormente le rappresentazioni. Il numero di livelli e la dimensione degli embedding sono iperparametri che determinano la capacità del modello. Il meccanismo di self-attention consente di catturare le relazioni tra i token all’interno della stessa sequenza, mentre il meccanismo di cross-attention assicura che l’output sia allineato contestualmente con l’input. Infine, le residual connections e la layer normalization sono critiche per stabilizzare l’addestramento e garantire un apprendimento efficace senza dispersione del gradiente.
Varianti della TA nei vari modelli moderni
Sulla base della documentazione disponibile, non è sempre possibile determinare l’architettura esatta utilizzata dai vari modelli, poiché i dettagli di progettazione rilevanti sono spesso solo parzialmente divulgati o, in molti casi, proprio non vengono condivisi. Di conseguenza, quanto diremo in questa sezione dell’articolo si basa anche su blog tecnici e discussioni specializzate online, che non possono essere considerate fonti ufficiali e che potrebbero presentare anche alcune affermazioni non del tutto affidabili. Tuttavia, incrociando le informazioni provenienti da diversi articoli, è stato possibile trarre le considerazioni che riportiamo di seguito.
Abbiamo visto come la Transformer Architecture [Vaswani et al., 2023] sia alla base dell’attuale fioritura di Large Language Models. Ma, negli anni, i moderni LLM si sono evoluti in architetture specializzate, adattate alle loro specifiche esigenze e a casi d’uso fondamentali.
Decoder-Only (modelli generativi)
La grande maggioranza dei moderni LLM utilizzati per chat e creazione di contenuti, tra cui GPT-4, Llama 3 e Claude, sembra utilizzare un’architettura Decoder-Only [Radford A. et al., 2018], [Touvron H. et al., 2023], [Belcic – Stryker, 2024]). Questa variante è diventata uno standard de facto per gli LLM. Questo design è ottimizzato per compiti auto-regressivi, in cui il modello prevede il token successivo in una sequenza per generare testo coerente.
Anche Gemini è costruito su una variante del decoder della TA standard, simile a GPT-4 e Llama, ma il disegno è stato modificato per gestire la “multimodalità nativa”. Quindi non si tratta solo di un decoder standard, ma è notevolmente adattato per input multimodali. Questo consente al singolo modello di elaborare e ragionare su più modalità (testo, immagini, audio, etc.), invece di aggiungere moduli separati per ciascuna modalità [Google Gemini Team, 2023].
Encoder-Only (modelli discriminativi)
I modelli progettati per la rilevanza nella ricerca, la classificazione e l’analisi del sentiment, come BERT e RoBERTa [Devlin J. et al., 2018], utilizzano un’architettura Encoder-Only. Questi modelli elaborano l’intera sequenza di input simultaneamente (bidirezionalmente) per comprendere il contesto, ma non sono progettati per generare testo.
Encoder-Decoder (modelli Seq2Seq)
Modelli come T5 (Google) e il Transformer originale mantengono entrambi gli stack, risultando molto efficaci per compiti sequence-to-sequence come la traduzione e il riassunto, anche se sono meno comuni nelle applicazioni di chat generiche.
La Transformer Architecture in sintesi
La TA è una rete neurale progettata specificamente per compiti di NLP (Natural Language Processing). A differenza di modelli meno recenti come le RNN (Recurrent Neural Networks) e le LSTM (Long Short-Term Memory networks), la Transformer Architecture elabora i dati sequenziali, come il testo, in parallelo anziché parola per parola, dimostrandosi significativamente più efficiente.
Vediamo di riassumere i servizi chiave che una TA deve implementare.
Catturare le relazioni tra i token
Ciò è possibile grazie al Self-Attention Mechanism, che permette al modello di comprendere le dipendenze tra le parole.
Concentrarsi su molteplici aspetti dell’input
Ciò è ottenuto grazie alla Multi-Head Attention, che elabora diverse relazioni in parallelo.
Fornire informazioni sull’ordine dei token
Ciò è gestito dal Positional Encoding, che codifica l’ordine sequenziale dei token.
Apprendere pattern complessi
Ciò è realizzato attraverso i Feed-Forward Layers, che trasformano le rappresentazioni dei token.
Stabilizzare e accelerare l’addestramento
Ciò è gestito dalla Layer Normalization, che assicura distribuzioni di input consistenti per ogni livello.
Mantenere le informazioni e migliorare il flusso del gradiente
Ciò è possibile grazie alle varie Residual Connections, che aiutano a preservare le informazioni dai livelli precedenti.
Facilitare i compiti sequence-to-sequence
La struttura Encoder-Decoder si occupa di questo processo, essenziale per compiti come la traduzione automatica.
Elaborare efficientemente grandi dataset
Questo servizio è ottenuto tramite la scalabilità e il parallelismo dell’architettura, che permettono al modello di elaborare i token simultaneamente.
Convertire il testo in rappresentazioni numeriche
La conversione del test avviene attraverso la tokenization e successiva trasformazione nei vettori Embedding, che trasformano il testo in un formato numerico elaborabile dal modello.
Generare predizioni o output
Questi servizi sono implementati dall’Output Layer, che produce i risultati finali.
Tutti questi componenti lavorano insieme per rendere la TA uno strumento potente e versatile per una vasta gamma di compiti, dalla traduzione automatica alla generazione di testo e oltre. La TA è particolarmente adatta per gli LLM (Large Language Models) per diverse ragioni:
- Parallelizzazione: a differenza di altre architetture come le RNN, i Transformer elaborano i token simultaneamente, consentendo un addestramento efficiente su larga scala.
- Comprensione contestuale: il meccanismo di self-attention cattura le relazioni tra le parole, indipendentemente dalla loro distanza nella sequenza, superando un limite dei modelli precedenti che spesso presentavano problemi di accuratezza nel processamento di lunghi testi.
- Scalabilità: le prestazioni dei Transformer migliorano in modo prevedibile all’aumentare della dimensione del modello e della quantità di dati di addestramento, seguendo “leggi di scala” (scaling laws) ben progettate.
- Transfer Learning: IiTransformer pre-addestrati possono essere perfezionati (fine-tuned) per un’ampia varietà di compiti a valle (downstream tasks), rendendoli altamente adattabili e riutilizzabili.
Conclusione
In conclusione, la TA ha di fatto rivoluzionato l’NLP fornendo un framework robusto, scalabile ed efficiente per la comprensione e la generazione del linguaggio umano. La sua capacità di elaborare grandi dataset, catturare relazioni complesse e adattarsi a diversi compiti la rende la spina dorsale dei moderni Large Language Models.
Riferimenti
[Vaswani et al., 2023] Ashish Vaswani – Noam Shazeer – Niki Parmar – Jakob Uszkoreit – Llion Jones – Aidan N. Gomez – Łukasz Kaiser – Illia Polosukhin, Attention is all you need. 2 August 2023,
https://arxiv.org/pdf/1706.03762.pdf
[Devlin J. et al., 2018] Jacob Devlin – Ming-Wei Chang – Kenton Lee – Kristina Toutanova, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
https://arxiv.org/abs/1810.04805
[Google Gemini Team, 2023] Google Gemini Team, Gemini: A Family of Highly Capable Multimodal Models.
https://arxiv.org/abs/2312.11805
[Radford A. et al., 2018] Alec Radford – Jeffrey Wu – Rewon Child – David Luan – Dario Amodei – Ilya Sutskever, Language Models are Unsupervised Multitask Learners”.
https://t.ly/4RI02
[Touvron H. et al., 2023] Hugo Touvron – Thibaut Lavril – Gautier Izacard – Xavier Martinet – Marie-Anne Lachaux – Timothée Lacroix – Baptiste Rozière – Naman Goyal, – Eric Hambro – Faisal Azhar – Aurelien Rodriguez – Armand Joulin – Edouard Grave – Guillaume Lample, LLaMA: Open and Efficient Foundation Language Models.
https://arxiv.org/abs/2302.13971
[Belcic – Stryker, 2024] Ivan Belcic — Cole Stryker, What is Claude AI?. IBM, September 2024.
https://t.ly/K5LV1