


Chatbot, memoria e aggiornamento in tempo reale
Negli ultimi anni, i chatbot e gli assistenti virtuali sono divenuti strumenti chiave per il supporto clienti e l’automazione dei processi. La loro capacità di comprendere il linguaggio naturale porta gli utenti a considerarli “intelligenti” e a credere che possano memorizzare e riutilizzare le informazioni fornite durante una conversazione.
In realtà, la maggior parte dei chatbot ha una memoria a breve termine: le informazioni vengono ricordate solo per la durata della singola conversazione e poi dimenticate (la cosiddetta short memory). Non aggiornano la propria conoscenza in tempo reale.
I limiti della memoria a breve termine
Questa limitazione non è solo un dettaglio tecnico, ma un ostacolo concreto per le aziende che utilizzano i chatbot per l’assistenza. Lo abbiamo sperimentato direttamente in un progetto per un nostro cliente, per il quale abbiamo realizzato un sistema RAG (Retrieval–Augmented Generation) capace di recuperare risposte dai manuali tecnici di macchinari industriali.
Durante l’uso, il cliente ha riscontrato che una risposta fornita dall’assistente era errata a causa di una documentazione di partenza non aggiornata. Dopo aver corretto il chatbot direttamente in chat, il cliente si aspettava che, alla richiesta successiva, l’assistente fornisse automaticamente l’informazione corretta. La mancanza di una “memoria persistente” ha evidenziato una necessità chiara: permettere all’assistente di aggiornare la propria conoscenza in tempo reale, senza dover attendere un nuovo ciclo di aggiornamento della base di dati.
La nostra soluzione basata su RAG
Il nostro progetto iniziale si basava su un’architettura RAG, un approccio che unisce il recupero di informazioni con la generazione di linguaggio naturale tramite un Large Language Model (LLM).
Il primo passo è stato costruire una base di conoscenza a partire dai manuali tecnici. Questa documentazione è stata elaborata e suddivisa in piccoli frammenti di testo, ognuno trasformato in un vettore numerico, o embedding.
Gli embeddings si trovano in uno spazio vettoriale: uno spazio matematico in cui la posizione di ciascun vettore è determinata dal significato semantico del testo di origine. Di conseguenza, testi con contenuti simili si trovano vicini tra loro, mentre quelli con significati diversi risultano più lontani. Questo è il cuore del motore di recupero semantico.
Architettura e implementazione
L’architettura della prima versione dell’applicazione si presentava in questo modo:

Come si può osservare nell’illustrazione, in questa prima architettura il processo di elaborazione di una query utente si articola nei seguenti passaggi:
- Ricezione della query: l’utente invia una domanda, che viene acquisita dal chatbot.
- Recupero semantico: la query viene trasformata in un embedding e confrontata con lo spazio vettoriale per trovare i frammenti di testo più simili, cioè le porzioni di documenti pertinenti alla richiesta.
- Generazione della risposta: i frammenti individuati vengono forniti al modello di linguaggio, che li utilizza per costruire una risposta contestualizzata.
- Restituzione del risultato: la risposta viene inviata all’utente, completando l’intero flusso.
Da RAG classico a sistema ad agenti
Per riuscire ad aggiornare la conoscenza del chatbot in tempo reale abbiamo trasformato il sistema RAG classico in un sistema ad agenti dotato di tools per decidere dinamicamente come interagire con la base di conoscenza.
Un tool in un sistema ad agenti è uno strumento che l’agente può utilizzare per estendere le sue capacità o eseguire specifiche operazioni che vanno oltre le sue capacità native.
Abbiamo progettato due tool principali: tool di aggiornamento della conoscenza e tool di conversazione.
Tool di aggiornamento conoscenza
Questo tool viene utilizzato quando l’utente fornisce una nuova informazione o corregge un dato. Il tool crea l’embedding del testo contenente le nuove informazioni e lo scrive in un database vettoriale separato, dedicato esclusivamente alla conoscenza aggiunta in tempo reale.

Tool di conversazione
Questo tool viene utilizzato quando l’utente pone una domanda. Il tool interroga entrambe le basi di conoscenza, quella originaria e quella aggiornata in real time, recuperando i frammenti di testo più rilevanti e passando il risultato al modello di linguaggio, che genera la risposta finale.

Avendo a disposizione i due tool l’architettura del sistema é evoluta e si presenta in questo modo:
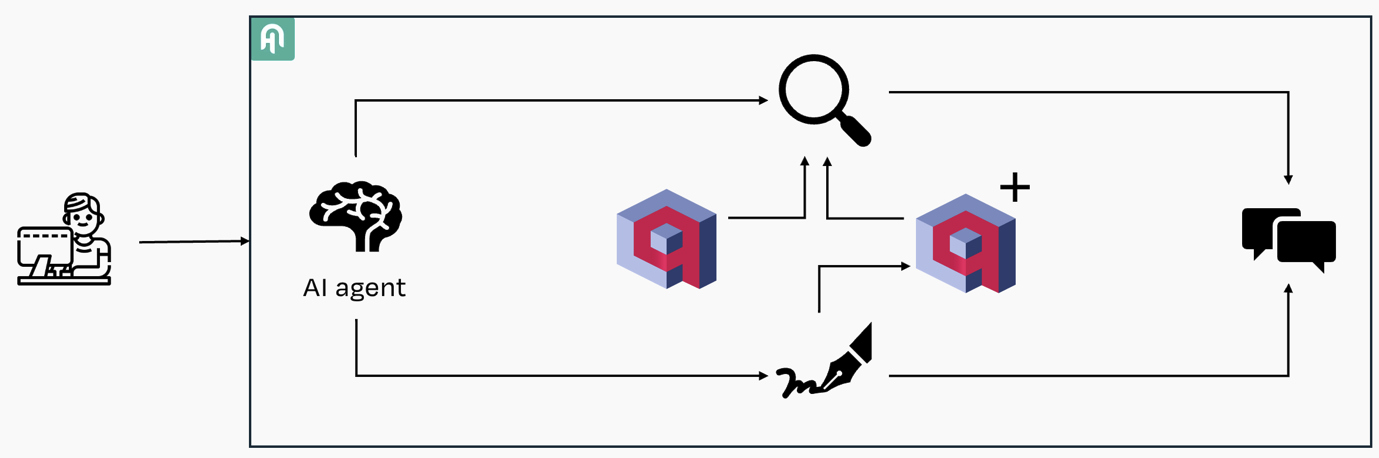
Il processo di elaborazione
Come si può osservare nell’illustrazione, In questa versione dell’applicativo che utilizza un agente il processo di elaborazione di una query utente è il seguente:
- Ricezione della query: l’utente invia una domanda, che viene acquisita dal chatbot.
- Selezione del tool appropriato: l’agente analizza il significato semantico della query e “capisce” se il messaggio rappresenta un aggiornamento di conoscenza o una semplice richiesta di informazioni. Nel primo caso passerà il messaggio al tool di aggiornamento della conoscenza, nel secondo caso utilizzerà il tool di conversazione
- Fusione dei risultati: in caso l’agente abbia utilizzato il tool di conversazione va a fondere i risultati delle due knowledge base per garantire che la risposta sia sempre aggiornata.
- Restituzione del risultato: una volta recuperate le informazioni queste vengono elaborate sempre attraverso un LLM per la generazione di una risposta.
L’introduzione di due basi di conoscenza separate ha portato con sé una sfida importante: la gestione delle contraddizioni. Se una stessa informazione è presente in entrambe le basi dati, ma in forma diversa, il sistema deve decidere quale considerare attendibile.
Per risolvere questo problema, abbiamo dato priorità alla knowledge base degli aggiornamenti real time. In questo modo, se la domanda dell’utente riguarda un contenuto che è stato aggiornato, la risposta restituita sarà sempre quella più recente, ignorando la versione obsoleta presente nella documentazione originale.
La scelta di mantenere due basi di conoscenza distinte è stata dettata da due motivi principali:
- Gestione semplificata degli aggiornamenti: I nuovi inserimenti e le correzioni diventano più facili da individuare, aggiornare o eventualmente eliminare, senza rischiare di compromettere la knowledge base originale.
- Performance del database vettoriale: Una volta generato lo spazio vettoriale della knowledge base principale, aggiungere o aggiornare gli embeddings comporterebbe un carico significativo in quanto il database deve re-indicizzare tutti i vettori per garantire le stesse prestazioni di ricerca. Separando i due spazi, il sistema mantiene alta la velocità di recupero, anche con aggiornamenti frequenti
Questa strategia permette quindi di bilanciare precisione delle risposte, manutenibilità del sistema e performance di ricerca, rendendo l’assistente più reattivo e affidabile.
Conclusioni
L’evoluzione dal classico sistema RAG a un sistema ad agenti con knowledge base dinamica ci ha permesso di superare una delle limitazioni più comuni dei chatbot: l’impossibilità di aggiornare la loro conoscenza in tempo reale.
Questo approccio non solo aumenta la precisione delle risposte e la soddisfazione dell’utente, ma riduce anche il tempo necessario per mantenere la base di conoscenza allineata alla realtà operativa del cliente.
Guardando al futuro, un’evoluzione naturale di questo sistema potrebbe essere l’automazione del processo di aggiornamento della documentazione. Le informazioni raccolte nella knowledge base real time, una volta validate e consolidate, potrebbero essere utilizzate per generare, in modo semi-automatico o automatico, nuove versioni dei manuali d’uso, mantenendoli sempre aggiornati senza richiedere un processo di revisione manuale lungo e complesso.
In questo modo, l’assistente virtuale diventerebbe non solo uno strumento di supporto, ma anche un motore attivo di miglioramento continuo della documentazione tecnica dell’azienda.