


Uno scenario comune
Provate a immaginare questa scena, che magari per molti non è immaginazione, ma vivida realtà: vi trovate in un open space immenso, nato dalla fantasia di un designer che credeva che la trasparenza e la collaborazione fossero la chiave per l’innovazione. Intorno a voi ci sono decine di colleghi, ognuno immerso nel proprio schermo, con cuffie colorate e antirumore, tastiere meccaniche, telefoni che squillano e persone che parlano e ridono in piedi in mezzo alla stanza.
Proprio in quel momento avete bisogno di interagire con la vostra AI preferita, dovete rispondere a un’email o avere un riassunto dell’ultima riunione, dovete dire a vostra moglie che per Natale volete regalare un “torrone” a vostro suocero, ma l’AI continua a capire “terrone” e vi ricorda che è un termine poco gradevole da dare a un vostro parente.
Cosa fate? Urlate come un pazzo “Fate silenzio!”? Andate in un angolo isolato del palazzo sperando che non passi nessuno a interrompervi? Andate in bagno e vi chiudete dentro sperando che nessuno vi creda un pazzo?
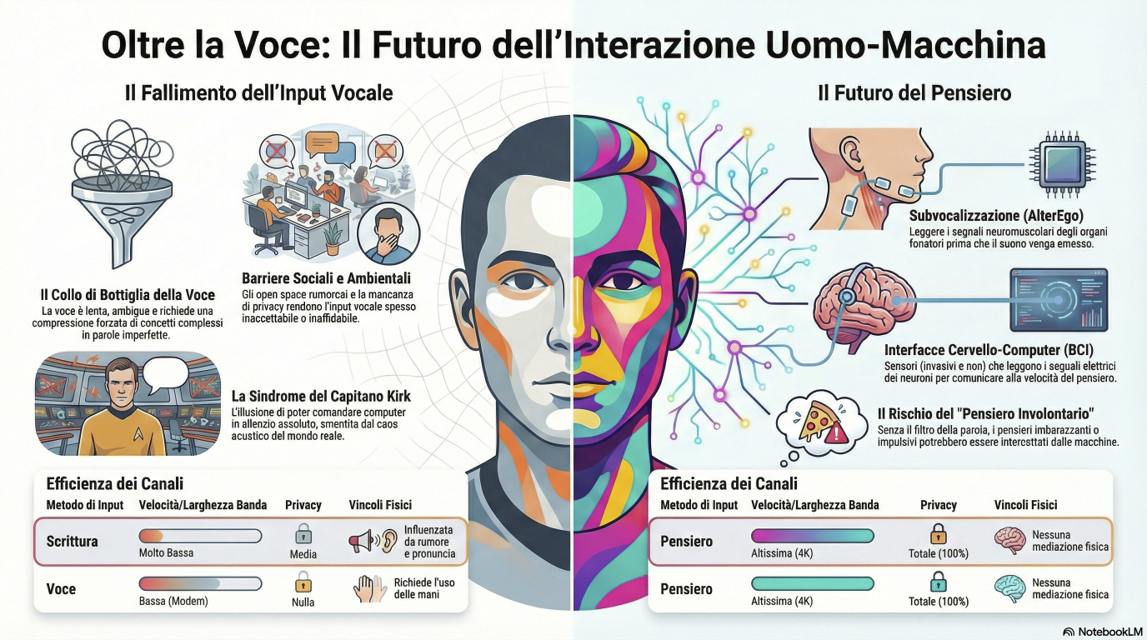
La sindrome del capitano Kirk
L’infanzia passata a guardare le puntate di Star Trek, dove il capitano Kirk riusciva a impartire ordini complessi al computer di bordo nell’assoluto silenzio della plancia dell’Enterprise, non può che rappresentare la romantica aspettativa di un futuro che è realizzabile solamente nel silenzio della propria stanza, ma quasi irrealizzabile in un mondo dove l’open space regna come unico strumento di socializzazione e la privacy è una necessità per quasi tutti.
Riflettiamoci: siamo convinti che questo sia il futuro? Siamo certi che l’apice dell’evoluzione tecnologica consista nel parlare da soli in una stanza vuota o nell’urlare comandi in un ambiente rumoroso sperando che un algoritmo di Natural Language Processing capisca la differenza fra “torrone” e “terrone” quando parlate con la vostra compagna?
E se fosse tutto un problema di input?
Se analizziamo con attenzione tutta la tecnologia che abbiamo sfornato negli ultimi anni, ci accorgiamo di un’asimmetria preoccupante. Abbiamo costruito un’infrastruttura di output eccezionale, ma siamo rimasti all’età della pietra per quanto riguarda l’input.

Proviamo a porci una domanda: e se stessimo sbagliando tutto? E se l’era degli assistenti vocali non fosse il punto d’arrivo, ma solo una goffa fase di passaggio, la classica patch temporanea in attesa di una soluzione vera? E se fossimo ancora in una sorta di era primitiva dove le nostre corde vocali che vibrano faticosamente nell’aria sono le schede perforate di tutto questo sistema?
Dalla voce al pensiero
Esploriamo un tipo di input diverso, dove il futuro non sia “parlare”, ma “pensare”. Facciamo una considerazione: la voce è un collo di bottiglia insostenibile per la larghezza di banda del nostro cervello. La voce ha tutta una serie di vincoli legati a come emettiamo i suoni, all’ambiente, alla pronuncia. Il pensiero no: è più veloce della voce, la sua comprensione non è influenzata dai rumori e ha una privacy uguale al 100% di quello che dobbiamo dire.

Preparatevi a mettere in discussione il vostro smart speaker e a guardare le vostre cuffie con occhi diversi. In uno dei futuri ipotetici del nostro metaverso, il parlare con i computer darà lo stesso stupore che sta dando oggi l’uso del telefono a disco ai ragazzi della Generazione Z.
L’asimmetria dell’interfaccia uomo-macchina
Per capire il problema delle interfacce attuali dobbiamo prima analizzare il contesto in cui operiamo. Viviamo in un paradosso tecnologico: abbiamo risolto in modo brillante metà del problema della comunicazione perché riusciamo a generare video, audio, testo alla velocità della luce, producendo montagne di dati, ma lasciamo l’altra metà in uno stato di caos disfunzionale.
Negli ultimi anni sono stati investiti miliardi per perfezionare il modo in cui le macchine inviano informazioni al nostro cervello attraverso il canale uditivo. Nuovo hardware e algoritmi evoluti ci hanno permesso di avere delle esperienze di ascolto talmente immersive da poter chiudere gli occhi e immaginarci in altri mondi: non siamo ancora negli Holodeck, ma la strada è quella.
Dagli altoparlanti gracchianti dei grammofoni ai dispositivi indossabili di altissima fedeltà che troviamo nelle nostre tasche, il salto è stato enorme. Una delle innovazioni chiave è stata la diffusione della cancellazione attiva del rumore, una tecnologia in grado di “ascoltare” il caos nel quale siamo immersi — traffico, colleghi rumorosi, aspirapolvere — e annullarlo in tempo reale con un’onda sonora di fase opposta.
Questa tecnologia crea una “bolla di privacy” acustica facendoci percepire solo il suono che arriva dalle cuffie che indossiamo, anche se ci aliena completamente dal mondo esterno.
Gli avanzamenti dell’output audio
Cosa abbiamo ottenuto da questo progresso tecnologico? Tre benefici chiave:
- Intimità digitale: la tecnologia di conduzione ossea e gli auricolari “open ear” permettono di sovrapporre l’audio digitale alla realtà fisica senza bloccare il canale uditivo. Possiamo ascoltare nostra moglie che vi chiede dove avete messo il sale mentre siete in riunione e la voce dei vostri colleghi vi arriva nel cervello come se fosse un pensiero impiantato.
- Ubiquità del canale: possiamo ricevere output ovunque. Ascoltare un audiolibro mentre facciamo la spesa, ricevere la lettura di una notifica WhatsApp durante una riunione, o farci guidare dal GPS mentre andiamo in bicicletta.
- Qualità e umanizzazione: la sintesi vocale ha raggiunto livelli di realismo imbarazzanti. Se ripensiamo alle prime voci robotiche, gli attuali modelli neurali generano voci indistinguibili da quelle umane, con inflessioni emotive, pause per respirare, variazioni di tono.
Per quanto riguarda l’output, la tecnologia ha fatto passi da gigante.
Il fallimento dell’input: il collo di bottiglia della voce
Bene, fantastico, eccezionale: possiamo ricevere molti più dati di quanti siamo in grado di assimilare. Ma quando dobbiamo dare noi i dati? In questo caso la tecnologia inciampa. L’input vocale soffre di limitazioni fisiche, sociali e cognitive che al momento nessuna tecnologia sembra poter risolvere nel breve termine.
Non è un problema di strumenti digitali: è un problema di interfaccia fisica. Le interfacce vocali presuppongono un ambiente ideale che raramente esiste nella vita reale: il silenzio o un rumore controllato. Senza questo punto di partenza, è molto alto il rischio di mischiare con dati fuori contesto i dati che invece intendiamo realmente fornire alla macchina.
Il mondo reale è pieno di caos acustico: musica di sottofondo, colpi di tosse, TV accese, vicini che parlano. In questo contesto, l’input vocale diventa problematico e inaffidabile.
I problemi si dividono in tre macro-categorie:
- L’effetto Cocktail Party: il cervello umano riesce a isolare una singola voce in una stanza affollata; è un processo naturale chiamato “attenzione selettiva”. È il motivo per il quale quando parliamo al tavolo di un ristorante con i nostri commensali riusciamo a isolarci, ma volendo possiamo totalmente concentrarci sui discorsi dei nostri vicini. Per un microfono, è una sfida algoritmica enorme. Nonostante le tecnologie attuali, il tasso di errore aumenta esponenzialmente in ambienti rumorosi.
- La guerra dei volumi: in un ambiente rumoroso chi vuole il sopravvento sul rumore degli altri tende ad alzare la voce. Questo trasforma un’interazione che dovrebbe essere fluida in uno scontro fisico, che espone ad alto stress e a una progressiva riduzione della privacy.
- Fatica vocale e cognitiva: parlare con un computer richiede sforzo. Le parole vanno scandite, le frasi create in modo che siano maggiormente comprensibili, evitando i sottintesi per non rischiare di dover ripetere mille volte la stessa frase. Questo crea un carico cognitivo e fisico che non esiste con il pensiero fluido o con la digitazione.
L’assenza di privacy dell’input vocale
Quante volte vi siete trovati in mezzo a un gruppo di persone e avete avuto imbarazzo a prenotare una visita proctologica? Quante volte non volevate far sapere che stavate cercando casa, o che avevate problemi in famiglia?
Esiste una barriera psicologica insormontabile nell’uso della voce in pubblico:
- Violazione della privacy: mandare un messaggio vocale con la password del vostro account condiviso in mezzo a un vagone ferroviario non è la scelta migliore. Chiedere a un’AI come curare delle malattie veneree potrebbe creare voci incontrollate sul vostro conto fra i colleghi. Mandare un messaggio al proprio commercialista su questioni fiscali delicate potrebbe far emergere informazioni che non volete che il mondo sappia. L’interfaccia vocale rende pubblico ciò che dovrebbe essere privato.
- Disturbo della quiete: in alcuni luoghi pubblici vige la regola del “silenzio”. In un ufficio “moderno”, se tutti parlassero con le loro IA contemporaneamente per gestire email, calendar e ricerche, il livello di rumore renderebbe impossibile lavorare. In molti open space esiste il divieto esplicito delle conversazioni ad alto volume, rendendo l’interfaccia vocale socialmente inaccettabile.
- La sindrome del pazzo: parlare con un oggetto, anche se questa pratica inizia a diventare socialmente accettata, vi fa sembrare un pazzo. Non avete mai pensato a questa cosa vedendo qualcuno in macchina che urlava e gesticolava da solo?
Portata dei canali di input
Se pensiamo alle modalità con le quali l’uomo produce input verso le macchine, possiamo classificare le interfacce in tre principali metodi:
- Pensiero: il flusso di dati più veloce e naturale, che avviene direttamente nel cervello, multimodale e parallelo.
- Voce: lenta, ambigua, influenzata dall’ambiente, richiede sforzo fisico e cognitivo.
- Scrittura: molto lenta, richiede l’uso delle mani, ma è precisa e strutturata.
Parlare è come provare a scaricare un film in 4K usando la connessione di un vecchio modem. Se usiamo la voce come input dobbiamo prendere un concetto complesso, comprimerlo in parole imperfette e sperare che la macchina comprenda correttamente il messaggio e ci restituisca un risultato pertinente.
È una compressione a perdita in cui gran parte delle sfumature vengono perse: usare in questo modo la voce degrada inesorabilmente la qualità.
Siamo primitivi?
Probabilmente stiamo cercando di montare un motore a curvatura su una carrozza a cavalli. Siamo abbagliati dalla potenza del motore, ma dimentichiamo che il sistema di trasmissione è obsoleto.
Siamo in un momento storico particolare. Stiamo dando accesso illimitato ai Large Language Models e come il capitano Kirk pensiamo di vivere in un futuro avanzato, ma l’interfaccia con cui nutriamo questa macchina è vecchia di millenni. L’apparato vocale umano si è evoluto per la comunicazione tribale a corto raggio. Questo tipo di comunicazione non è pensata per l’interazione uomo-macchina ad alta velocità e alta densità di dati.
Siamo quindi portati a ridurre la complessità dell’interazione, tendiamo a semplificare e linearizzare l’informazione, nascondendo le opzioni e le sfumature che un’interfaccia visiva o testuale potrebbe mostrare. Andando in questa direzione stiamo addestrando le IA a essere oracoli sintetici e superficiali invece che strumenti di analisi profonda, semplicemente perché chiedere cose complesse a voce è estremamente faticoso.
Se vogliamo muoverci più velocemente dobbiamo ripensare l’interfaccia di input, a un meccanismo che ci permetta di comunicare con le macchine a una velocità maggiore.
E se usassimo il pensiero?
L’input più performante di cui disponiamo è il pensiero: veloce, preciso, silenzioso e privato. Perché quindi non sostituire lo strumento di input vocale con uno strumento di input basato sul pensiero?
Qualcuno si è posto questa domanda e ha iniziato a lavorare su due grandi scuole di pensiero tecnologico:
- l’approccio non invasivo, utilizzando i micro movimenti del volto;
- l’approccio diretto e invasivo, con sensori impiantati nel cervello.
Subvocalizzazione
Esiste un progetto del MIT chiamato AlterEgo [1] che utilizza la subvocalizzazione come input. Il concetto è abbastanza semplice: leggere l’intento motorio della parola. Quando leggiamo in silenzio o parliamo “nella nostra testa”, il nostro cervello invia segnali neuromuscolari molto deboli agli organi fonatori e, anche se non emettiamo alcun suono, è possibile intercettare questi segnali. Questo fenomeno fisiologico si chiama subvocalizzazione.

Il dispositivo assomiglia a degli auricolari con microfono che dall’orecchio arrivano al mento, intercetta i segnali elettrici emessi dal cervello e li traduce in parole.
Con un oggetto del genere risolviamo in modo elegante una serie di problemi legati alla voce, senza utilizzare apparati dannosi e invasivi. Nessun problema di privacy, nessun problema di rumore, nessun problema di imbarazzo sociale.
Approccio invasivo
Se invece permettiamo a un’azienda di farci un piccolo buco nella testa, possiamo sperimentare l’ultima frontiera della tecnologia: le Brain-Computer Interfaces. Se AlterEgo legge i muscoli, le BCI leggono direttamente i neuroni.
Aziende come Neuralink, Synchron, Precision Neuroscience e altre stanno cercando di saltare completamente la mediazione fisica dei muscoli del corpo.
L’obiettivo è scavalcare completamente la bocca e le mani e leggere direttamente i segnali elettrici del cervello, decodificarli e inviarli al computer: maggiore velocità di pensiero, nessun rumore, nessun problema di privacy, effetti immediati fra uomo e macchina.
Questo futuro è ancora lontano, ma i progressi fatti negli ultimi anni sono impressionanti e ci fanno intuire tutte le problematiche legate a questa tecnologia e a un eventuale controllo sociale possibile attraverso di essa.
L’obiettivo verso il quale tutti stanno provando ad andare è quello di aumentare la larghezza di banda alla radice. Se riusciamo a intercettare l’intento prima che si propaghi nel corpo, riusciremo a comunicare con le macchine alla velocità del pensiero.
Quanto siamo lontani dalla fusione uomo-macchina?
Alcuni studi della Stanford University [2] hanno dimostrato che la capacità di decodificare il parlato immaginato è simile alla velocità della conversazione naturale e supera quella della digitazione media su smartphone.
A differenza di AlterEgo, le BCI ad alte prestazioni richiedono interventi chirurgici invasivi. Finché questo “piccolo” problema non sarà risolto, le BCI rimarranno confinate a casi medici estremi: tetraplegici, pazienti con SLA o comunque situazioni non sanabili con la normale medicina. Difficile — ma non impossibile — che una persona sana decida di farsi impiantare un chip nel cervello per migliorare la propria produttività lavorativa.
Purtroppo, o forse sarebbe meglio dire “fortunatamente”, il nostro cranio è stato pensato per proteggere il cervello da danni esterni, e qualsiasi intervento chirurgico comporta rischi significativi di infezione, rigetto e danni neurologici.
È vero anche che esistono BCI non invasive, sebbene al momento non abbiano le stesse “prestazioni” rispetto a un intervento invasivo.
E quando diventeremo macchine?
Una volta compreso che gli attuali meccanismi di input sono poco performanti, e che la tecnologia tramite massicce campagne di marketing potrebbe farci sembrare naturale accettare delle BCI invasive o no, dobbiamo iniziare a domandarci quali sono i pro e i contro di queste tecnologie.
Da un certo punto di vista la cosa fa paura, anche perché la lentezza è sempre stata una protezione contro eventuali disastri: cosa succederà se non avremo più questa barriera? Stiamo realizzando il guanto di Thanos e lo stiamo dando in mano a chiunque.
Dobbiamo interrogarci su tutti i pensieri “involontari” che potrebbero essere intercettati da questi dispositivi: siamo sicuri di voler aprire la porta della nostra mente? Quante volte avete pensato qualcosa di imbarazzante e non l’avete detto ad alta voce? E se un dispositivo fosse in grado di intercettare questi pensieri? Probabilmente quasi tutti noi rischieremmo un processo per qualche reato, anche se commesso solo a livello di pensiero… Pensate a tutti i momenti di odio nei quali avreste ucciso il vostro capo gettandolo dalla finestra, o a un eventuale automa collegato al vostro pensiero: quanto sarebbe distopico il nostro futuro?
E parliamo di hacking: basterebbe manipolare un pensiero per creare danni enormi. “Da grandi poteri derivano grandi responsabilità”.
Il transumanesimo è il nostro futuro?
Per chi sostiene le BCI il mantra più ascoltato è: “Se non puoi batterli, unisciti a loro”. In un mondo dove le macchine, poco alla volta, diventeranno più intelligenti e veloci di noi, è inutile cercare di competere: dobbiamo fondere la nostra mente con la loro. La regina Borg sarebbe fiera di noi.
Aumentare la mole di dati scambiati da noi alle macchine ci permette di avere interazioni sempre più veloci ed efficienti e questo “dovrebbe” migliorare la nostra vita.
Siamo in pieno refactoring evolutivo
Siamo pronti a lasciare il “rumore” per abbracciare il “segnale”? Il diritto alla lentezza, alla riflessione, a prendersi del tempo per pensare, è qualcosa che milioni di anni di evoluzione ci hanno donato per proteggerci dagli errori. Quello che vediamo come un limite potrebbe essere in realtà la nostra ancora di salvezza.
Tra vent’anni, quando i nostri figli ci chiederanno perché digitiamo ancora sulla tastiera invece di pensare direttamente al computer, cosa risponderemo?
Siamo dei cavernicoli che hanno imparato a giocare con la sabbia o siamo persone consapevoli che hanno capito che muoverci alla velocità del pensiero può creare più danni che opportunità? Il futuro non è inevitabile. Il futuro è una sommatoria di scelte che facciamo ogni giorno. Possiamo scegliere quale tipo di interfaccia utilizzare per connetterci con un apparato che abbiamo costruito, ma ogni volta che facciamo queste scelte prendiamo una decisione che ci definisce.
L’interfaccia vocale è tecnologicamente limitata, ma rappresenta un compromesso fondamentale: mantenere una distanza fra noi e quello che abbiamo creato. Le nuove interfacce ci promettono di eliminare questo filtro, lo dipingono come un limite, ma forse è proprio il limite che ci protegge ed evita la perdita di contatto umano.
Il clean code ci ha insegnato che il miglior refactoring è quello che ci aiuta a capire meglio quello che facciamo, non quello che ci fa accelerare a costo della comprensibilità. È quello che ci aiuta a non fare errori, non quello che ci fa fare più cose in meno tempo.
La lentezza, l’imperfezione e gli errori sono un simbolo di umanità, un aspetto che dobbiamo preservare e non dovremmo mai voler ottimizzare.
Riferimenti
[1] Il progetto AlterEgo, basato sulla subvocalizzazione
https://www.media.mit.edu/projects/alterego/overview/
[2] Miryam Naddaf, Dispositivi di lettura del cervello permettono di parlare usando il pensiero. Le Scienze
https://tinyurl.com/2cj3k53s