


Introduzione
Immagina il seguente scenario: sei completamente concentrato, immerso nello sviluppo del tuo software. Stai lavorando assistito da Claude Code con rapide iterazioni prompt, Claude Code output, revisione dei risultati, perfezionamento, e così via. Tutto sembra veloce, quasi senza attriti. Le funzionalità prendono forma in pochi minuti. Modifichi, migliori e vai avanti speditamente.
Poi, all’improvviso, ti scontri con un ostacolo imprevisto:
Hai raggiunto il limite. Devi attendere alcune ore oppure effettuare un upgrade per aumentare il limite di utilizzo.
Lo slancio svanisce. Il tuo flusso viene interrotto. Non si tratta di un raro caso limite. Succede spesso, anche nelle ore non di punta, persino quando hai deciso di aggiornare il tuo abbonamento a un piano Max. Ti rendi conto immediatamente che i token sono una risorsa finita e sorprendentemente volatile. E che, nella maggior parte dei casi, non vengono utilizzati nel modo più efficiente possibile.
I token e il loro utilizzo
In questo articolo e nel successivo, vedremo di capire un po’ meglio questo meccanismo. In particolare, in questa prima parte illustremo i concetti di token e tokenizazione, il che ci permetterà, nella seconda parte il mese prossimo, di illustrare strategie pratiche per aiutare gli sviluppatori a ottenere il massimo da ogni token, così da mantenere più a lungo il flusso di lavoro, ridurre gli sprechi e rendere l’utilizzo di Claude Code molto più efficiente e stimolante.
Chiaramente, anche se ci concentreremo su Claude Code, che è uno degli strumenti più diffusi per lo sviluppo, in realtà in concetti e i suggerimenti presentati sono applicabili a diversi modelli LLM che supportano lo sviluppo software.
Che cosa è un token?
Un token è la più piccola unità di testo che un modello linguistico (LLM) legge e utilizza ai fini della fatturazione. Per semplicità, si può pensare a un token come a una parola, ma si tratta solo di un’approssimazione.
Secondo OpenAI [OpenAI 2026], i token sono i mattoni fondamentali del testo che i modelli elaborano. Possono essere lunghi quanto un singolo carattere oppure quanto un’intera parola, a seconda della lingua e del contesto. Spazi, punteggiatura e persino parti di parole contribuiscono tutti al conteggio totale dei token. Analizzando testi in lingua inglese, è possibile ricavare delle indicazioni empiriche che danno un “valore” ai token.

Come si può vedere in tabella 1, un token può “coprire” l’elaborazione di parole estremamente brevi ma, per elaborare una parola più lunga di pochissimi caratteri, i nostri LLM devono spendere più di un token.
Il processo di tokenizzazione
In modo semplificato, cosa succede quando inviamo un prompt a un modello? In pratica, il testo viene scomposto in “mattoncini”, i token appunto, vale a dire negli elementi costitutivi: piccoli gruppi di caratteri, parti di parole, elementi grammaticali etc. Questo processo di scomposizione è chiamato tokenizzazione.
Successivamente alla tokenizzazione in input, il modello elabora i token appena creati dalla scomposizione del testo.
Poi la risposta viene generata internamente dal LLM come sequenza di token.
Infine, questi token in output vengono convertiti nuovamente in testo e restituiti come risposta.
![Figura 1 – Esempio di tokenizzazione. Il numero 13 identifica il punto [OpenAI 2026].](https://mokabyte.it/wp-content/uploads/2026/06/costotoken-1_fig01.jpg)
Categorie di utilizzo dei token
Attenzione però, poiché il processo è un po’ più complesso; infatti non ci sono solo i token in input e quelli in output, ma il quadro è articolato come segue:
- token di input: token presenti nella richiesta (nel prompt);
- token di output: token generati nella risposta;
- Token memorizzati in cache: token riutilizzati dalla cronologia della conversazione (spesso fatturati a una tariffa ridotta);
- Token di ragionamento (reasoning tokens): in alcuni modelli avanzati, vengono utilizzati passaggi interni di “ragionamento” aggiuntivi prima di produrre l’output finale.
La “fatturazione” dei token
Diversi LLM utilizzano un modello tariffario basato sui token, il che significa che gli addebiti agli utenti sono basati sulla quantità di testo che il modello elabora e genera. La tariffazione basata sui token mira ad allineare il prezzo all’effettivo utilizzo delle risorse di calcolo e a offrire un controllo dettagliato sulla spesa. Claude Code segue questo approccio e addebita i costi in base al consumo di token tramite API.
È possibile utilizzare il comando “/cost” per mostrare l’utilizzo dei token API ed è pensato per gli utenti API. Tuttavia, per gli abbonati Claude Max e Pro, l’utilizzo è incluso nell’abbonamento, quindi i dati di /cost non sono direttamente rilevanti per la fatturazione. Gli abbonati possono invece usare /stats per comprendere meglio i propri modelli di utilizzo, come spiegato nella documentazizone di Claude.
Dentro il funzionamento, tra efficacia e risparmio
I token, quindi, non sono solo un dettaglio tecnico, ma rappresentano un budget reale e limitato a nostra disposizione per effettuare elaborazioni di tipo diverso, tutte comunque costose in termini di potenza computazionale e, quindi, di consumo di energia. In pratica:
- ogni prompt ha un costo;
- ogni risposta ha un costo;
- ogni iterazione ha un costo cumulativo.
Ecco perché i token possono esaurirsi così rapidamente e perché gestirli in modo efficace è fondamentale quando si sviluppa software con LLM come Claude.
CLAUDE.md
CLAUDE.md è un file descrittivo e di istruzioni a livello di progetto scritto in linguaggio MarkDown e utilizzato per guidare il comportamento del modello Claude all’interno di uno specifico progetto.
In genere contiene un contesto persistito che include standard di codifica, linee guida architetturali, librerie e strumenti preferiti, moduli software, dipendenze, richieste specifiche a Claude — cosa deve e cosa non deve fare — e così via. Quando presente, il suo contenuto viene incluso nel contesto del modello, il che significa che Claude “legge” e segue queste istruzioni insieme alla conversazione.
Ciò consente ai team di applicare comportamenti coerenti, produrre software più affidabile e standardizzato e ridurre la necessità di ripetere le stesse indicazioni in ogni prompt, continuando al contempo a beneficiare della capacità del modello di adattarsi dinamicamente. Però, come vedremo, tutto ciò ha un costo.
MCP
Il Model Context Protocol (MCP), protocollo per il contesto del modello, è uno standard open-source che consente alle applicazioni AI di connettersi a sistemi esterni. Utilizzando MCP, modelli come Claude o ChatGPT possono interagire con fonti di dati (ad esempio file locali o database), strumenti (ad esempio motori di ricerca o calcolatori) e flussi di lavoro (ad esempio prompt specializzati), permettendo loro di recuperare informazioni ed eseguire azioni oltre le loro capacità native.
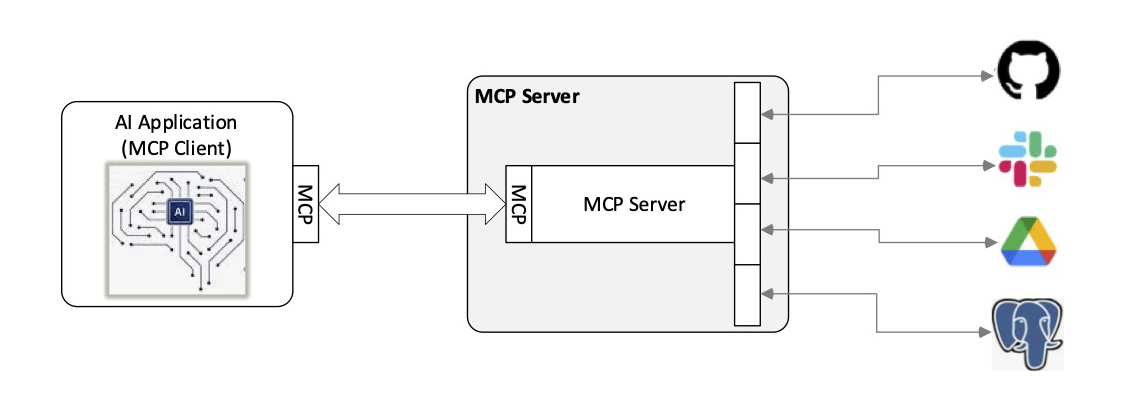
MCP standardizza il modo in cui i sistemi di intelligenza artificiale si integrano con strumenti e servizi esterni. Attraverso MCP, modelli come Claude Code possono creare integrazioni con un’ampia gamma di risorse esterne, con i server MCP che fungono da connettori ed espongono capacità via API a database, file system, etc.
Un ecosistema in continua crescita di server MCP è già disponibile. Tra gli esempi vi sono il Filesystem MCP Server, che fornisce accesso a file e directory locali; il GitHub MCP Server sviluppato da GitHub, che consente l’interazione con repository issue e pull request; il PostgreSQL MCP Server per PostgreSQL, che supporta query strutturate su database; lo Slack MCP Server sviluppato da Slack, che si collega ai canali di comunicazione dei team; e il Google Drive MCP Server di Google, che permette l’accesso a documenti e file. Inoltre, aziende come PayPal hanno sviluppato server MCP per consentire ai commercianti di svolgere attività operative utilizzando il linguaggio naturale tramite client compatibili. Questi sono solo alcuni esempi dei server MCP già disponibili.
Conversazione: il passato pesa
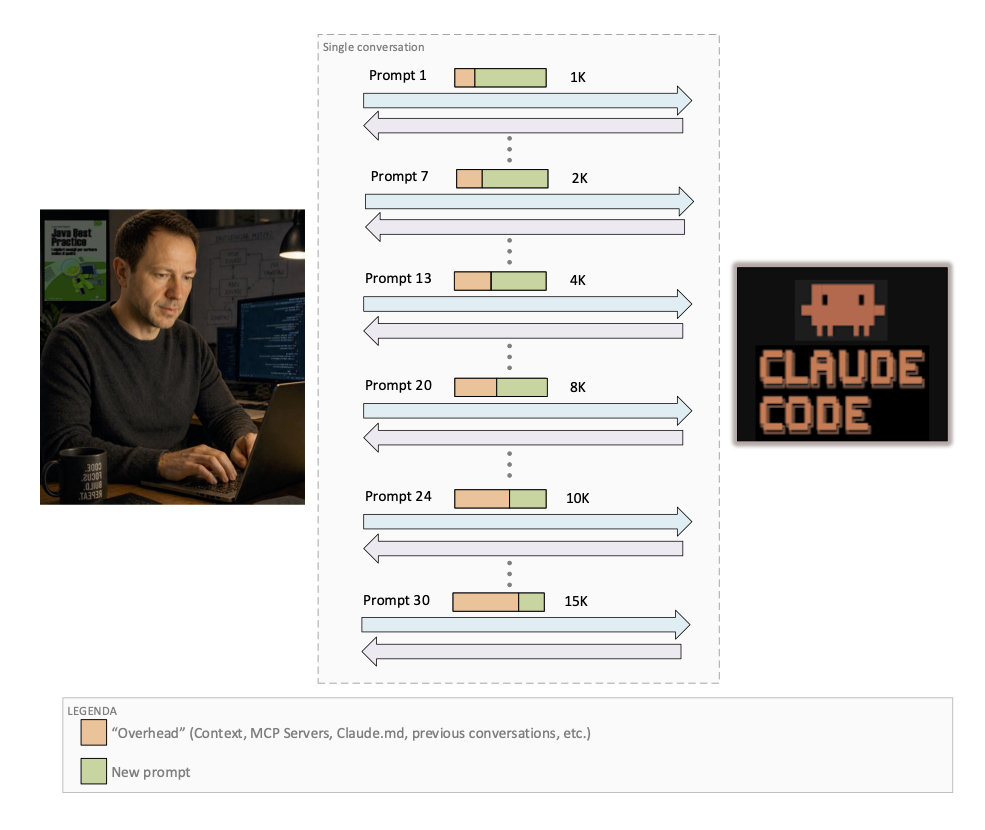
Ogni volta che interagiamo con Claude Code e inviamo prompt, il modello elabora l’intera cronologia della conversazione come parte del contesto di input. Ciò significa che, a ogni nuovo prompt appartenente alla stessa conversazione, il modello rilegge e ragiona su tutti gli scambi precedenti, dal primo messaggio fino al più recente. Inoltre, il modello non legge solo i nostri prompt e le relative risposte, ma anche eventuali materiali aggiuntivi come documentazione di sistema (ad esempio CLAUDE.md), strumenti connessi (server MCP), file di riferimento, competenze e altri dati contestuali.
Con l’aumentare della lunghezza del contesto aumentano anche il costo computazionale e la complessità [Lee, 2025]. In un classico ciclo di sviluppo, questo aspetto può portare a inefficienze significative e costi elevati se non gestito con attenzione.
Di conseguenza, il consumo di token cresce progressivamente a ogni interazione: ogni nuovo prompt è più costoso del precedente perché include un contesto più ampio.
Lost in the middle
Oltre al costo, esiste anche una considerazione legata alla qualità. La ricerca ha individuato un fenomeno noto come effetto “lost in the middle” (perso nel mezzo, o effetto di perdita di rilevanza nella parte centrare, [Liu et al., 2023]). I modelli linguistici tendono a prestare maggiore attenzione alle informazioni presenti all’inizio e alla fine di un prompt, mentre quelle al centro hanno maggiore probabilità di essere trascurate.
Gli studi mostrano che le prestazioni del modello sono massime quando le informazioni rilevanti compaiono all’inizio o alla fine del contesto e peggiorano quando sono “sepolte” nella parte centrale. In termini pratici, ciò significa che, con l’aumentare della lunghezza delle conversazioni, queste non solo diventano più costose, ma anche meno affidabili, rendendo essenziale gestire attivamente il contesto, strutturare con attenzione i prompt, prestare attenzione alla lunghezza della conversazione e alla dimensione del messaggio, evitando un accumulo inutile di token.
Conclusioni
Per questo mese ci fermiamo qui. In questo articolo abbiamo voluto fornire una definizione di token e qualche riferimento sul funzionamento dei meccanismi interni agli LLM che proprio sul consumo di token si basano. Come avete potuto leggere, il quadro, per quanto abbastanza chiaro, non è affatto semplicistico come si potrebbe pensare.
Proprio partendo da queste conoscenzei, nel prossimo numero esamineremo alcune indicazioni tecniche pratiche che ci consetono di risparmiare token, pur mantenendo elevata l’efficacia dell’elaborazione.
Riferimenti
[OpenAI 2026] What are tokens and how to count them?
https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them
[Lee 2025] Timothy B. Lee, Context rot: the emerging challenge that could hold back LLM progress.
https://www.understandingai.org/p/context-rot-the-emerging-challenge
[Liu et al. 2023] Nelson F. Liu – Kevin Lin – John Hewitt – Ashwin Paranjape – Michele Bevilacqua – Fabio Petroni – Percy Liang, Lost in the Middle: How Language Models Use Long Contexts.
https://arxiv.org/abs/2307.03172
[Madabhushi 2026] Ravi Madabhushi, MCP is up to 32× more expensive than CLI. Here’s why we still use it.
https://www.scalekit.com/blog/mcp-vs-cli-use